Interpretable Spatio-Temporal Modeling
Combined ensemble learning and the multi-Markov-Blankets concept in Bayesian probability theory to provide accurate predictions of extreme precipitation events.
The work on this project has published in ICNSC 2016 and ICBK 2018. Take a look at “An evaluation of big data analytics in feature selection for long-lead extreme floods forecasting” and “Galaxy: Towards Scalable and Interpretable Explanation on High-Dimensional and Spatio-Temporal Correlated Climate Data” for more details.
Objective
Given a large-scale spatiotemporal database, effectively and efficiently identifying strongly related features and removing irrelevant or less important features with respect to a target variable is a critical and challenging issue in many fields. The optimal sub-feature-set that contains all valuable information is called the Markov Boundary. Unfortunately, existing feature selection methods often focus on identifying a single Markov Boundary, while real-world data could have many feature subsets that are equally good boundaries. In our work, we studied the state-of-the-art streaming feature selection methods and evaluated them on meteorological data to identify the precursors of heavy precipitation event clusters. Additionally, we designed a new predictive model called Galaxy that is based on multiple Markov boundaries for long-lead rainfall forecasting.
Streaming feature selection on large-scale Spatio-temporal database
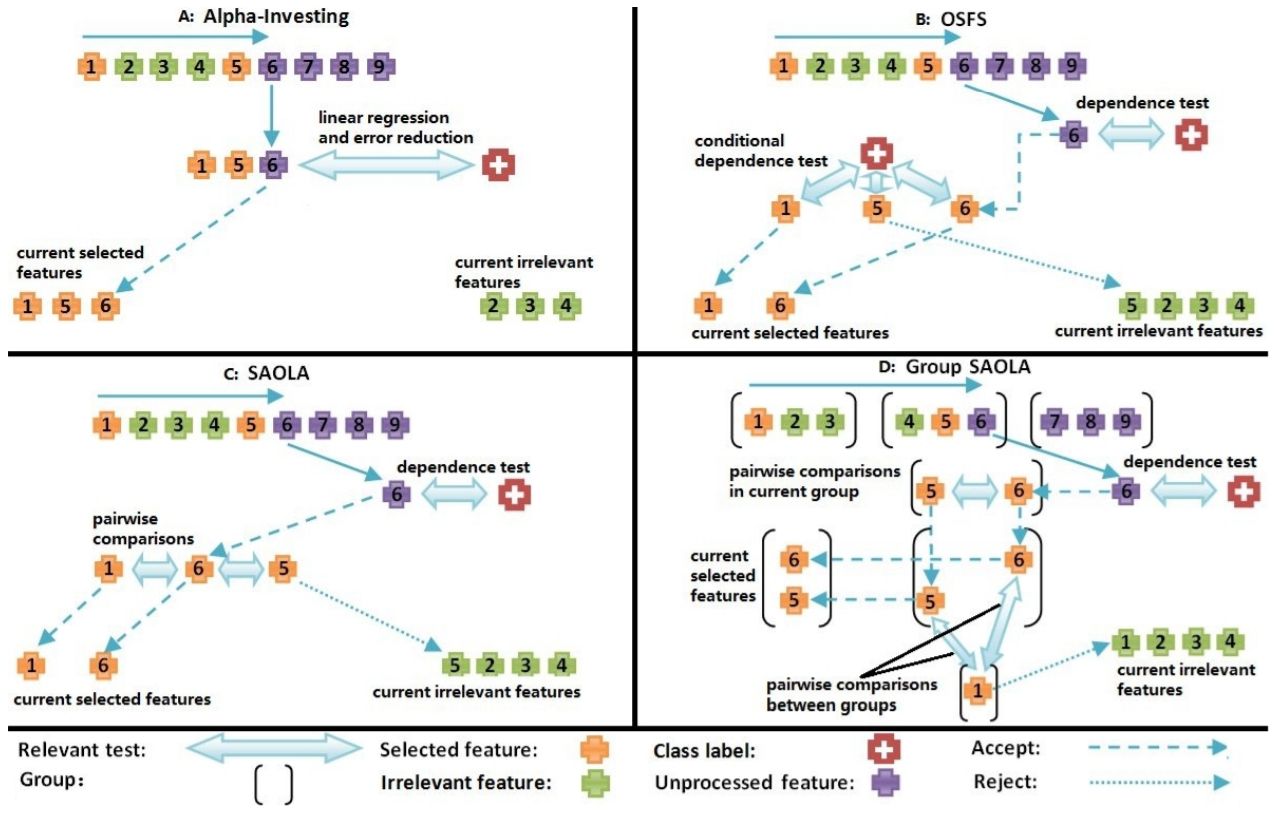 In practical Spatio-temporal applications, the transformation and interaction of a small set of original features can lead to a combinatorial increase in the feature set size. For example, in a flooding forecasting problem, considering interactions between nine original meteorological features in 5,328 locations over ten days led to over 479,520 potential features. Streaming feature selection is a superior technique for interweaving the feature generation process with the feature testing process to avoid generating unhelpful features. It continuously updates the subset of predicted features through correlation analysis of newly emerging, target, and selected features to remove irrelevant and redundant features and select the most relevant ones. We evaluated four state-of-the-art streaming feature selection methods (Alpha-investing, Online Streaming Feature Selection (OSFS), Scalable and Accurate Online Approach (SAOLA), and Group SAOLA) on meteorological data sets to identify the precursors to heavy precipitation event clusters.. Through online redundancy analysis, OSFS significantly reduces the learning complexity by selecting only 68 features from 479,520 candidate features, while Alpha-investing selects 112. OSFS provides a more accurate precursor feature set with the most potent ability to predict heavy rain events. However, SAOLA and Group SAOLA, with the effort of online pairwise comparisons and group information, only select 15 and 8 features, respectively. The performance of predictive models using the selected feature sets is still comparable.
In practical Spatio-temporal applications, the transformation and interaction of a small set of original features can lead to a combinatorial increase in the feature set size. For example, in a flooding forecasting problem, considering interactions between nine original meteorological features in 5,328 locations over ten days led to over 479,520 potential features. Streaming feature selection is a superior technique for interweaving the feature generation process with the feature testing process to avoid generating unhelpful features. It continuously updates the subset of predicted features through correlation analysis of newly emerging, target, and selected features to remove irrelevant and redundant features and select the most relevant ones. We evaluated four state-of-the-art streaming feature selection methods (Alpha-investing, Online Streaming Feature Selection (OSFS), Scalable and Accurate Online Approach (SAOLA), and Group SAOLA) on meteorological data sets to identify the precursors to heavy precipitation event clusters.. Through online redundancy analysis, OSFS significantly reduces the learning complexity by selecting only 68 features from 479,520 candidate features, while Alpha-investing selects 112. OSFS provides a more accurate precursor feature set with the most potent ability to predict heavy rain events. However, SAOLA and Group SAOLA, with the effort of online pairwise comparisons and group information, only select 15 and 8 features, respectively. The performance of predictive models using the selected feature sets is still comparable.
Identify multiple Markov boundaries in large-scale Spatio-temporal database
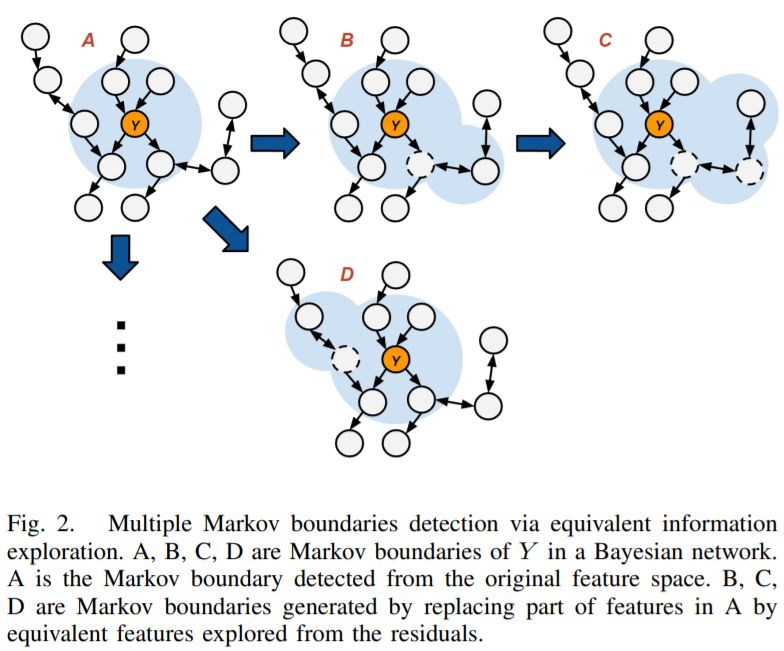 The ultimate goal of the feature selection method is to identify the feature set most relevant to the target feature, which is called the Markov boundary. In an ideal situation, the joint probability distribution \(P\) is faithful to the graph of the Bayesian network \(G\), there exists a unique Markov boundary for the target variable. However, the faithfulness condition rarely holds in real-world data due to factors such as hidden variables, hypothesis test errors, and spurious correlations, which can make the Markov boundary of the target variable non-unique. To address this issue, we designed a novel algorithm to identify multiple Markov boundaries through equivalent information exploration. Specifically, We first determine a Markov boundary \(M\), and then attempt to replace a sub-feature-set \(A \in M\) with a potential equivalent feature set \(B\) explored from the residual features through correlation and performance analysis, getting a new Markov boundary \(M'\). We repeated this process and combined it with ensemble learning to design a long-lead forecasting model named Galaxy for predicting extreme precipitation events. We applied Galaxy to an extremely high-dimensional meteorological data set and finally determined 15 Markov boundaries related to heavy rainfall events in the Des Moines River Basin in Iowa, where the smallest size is four and the largest size is 13. Galaxy identified the cold surges along the coast of Asia as an essential precursor to the surface weather over the United States, and this finding was subsequently confirmed by climate experts.
The ultimate goal of the feature selection method is to identify the feature set most relevant to the target feature, which is called the Markov boundary. In an ideal situation, the joint probability distribution \(P\) is faithful to the graph of the Bayesian network \(G\), there exists a unique Markov boundary for the target variable. However, the faithfulness condition rarely holds in real-world data due to factors such as hidden variables, hypothesis test errors, and spurious correlations, which can make the Markov boundary of the target variable non-unique. To address this issue, we designed a novel algorithm to identify multiple Markov boundaries through equivalent information exploration. Specifically, We first determine a Markov boundary \(M\), and then attempt to replace a sub-feature-set \(A \in M\) with a potential equivalent feature set \(B\) explored from the residual features through correlation and performance analysis, getting a new Markov boundary \(M'\). We repeated this process and combined it with ensemble learning to design a long-lead forecasting model named Galaxy for predicting extreme precipitation events. We applied Galaxy to an extremely high-dimensional meteorological data set and finally determined 15 Markov boundaries related to heavy rainfall events in the Des Moines River Basin in Iowa, where the smallest size is four and the largest size is 13. Galaxy identified the cold surges along the coast of Asia as an essential precursor to the surface weather over the United States, and this finding was subsequently confirmed by climate experts.